The Wilcoxon Signed Rank Test calculator provides the Wilcoxon statistics and critical value for two groups of numeric observations based on an alpha value and whether it's a one or two tailed test.
INSTRUCTIONS: Enter the following:
- (Group 1, Group 2) Table of comma separated values for group 1 and 2.
- (Tails) Choose 1 or 2 for either a one or two tailed test.
- (α) Choose an alpha value from the list for the statistical test.
Wilcoxon Stat and Critical Value: The calculator will return the Wilcoxon statistic (Wstat) and the critical value (Wcrit) associated with the sample size, alpha value and number of tails.
The Math / Science
The Wilcoxon signed rank test is a non-parametric alternative to the paired samples t-test (Gravetter and Wallnau, 2013) that is useful when one or both of the observation groups are not normally distributed. Just like a paired-samples design, it measures the difference between two treatments on a sample that receives both treatments. Since it is non-parametric, it is only used if the data fail to meet the parametric assumptions; for instance, the data might not create a normal distribution. Therefore, instead of using the data points in the formula, the Wilcoxon test assigns every value a rank and uses the rank to compute the W value.
Example One
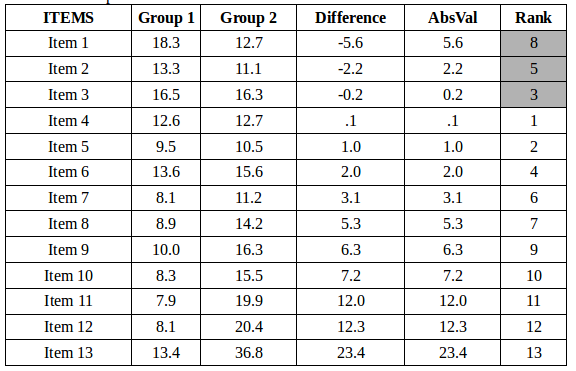
The numbers in the above table match the tutorial in the following YouTube video: CLICK HERE.
The null hypothesis is in regard to the median of the two groups:
Ho MedianGroup1 = MedianGroup2
Steps:
- Confirm that Group 1 has the same number as Group 2 and that the scores are paired (this means that the first score from Group 1 should come from the same participant as the first score from Group 2 and that all other scores should be entered similarly as pairs). The number of pairs (n) is used to look up the critical value (Tcrit) which is 13 in the example above.
- Compute the difference between the pairs in the group. This is the Difference column above.
- Compute the absolute value of the differences. This is the AbsVal column above.
- Rank the absolute values from smallest to greatest (see Ranking Special Cases).
- Sum up the ranks for the positive differences (S+) and the negative difference (S-). The Wilcoxon Stat (Wstat) is the smaller of the two. In the case above, S- is 16 (gray area above) and S+ is 75
If you look up the Critical Value for a Wilcoxon two tailed test with alpha equal 0.05, you'll see a critical value of 17. Since Wstat of 16 is less than Wcrit of 17, the null hypothesis is rejected.
Ranking Special Cases
- Omit ranking anything with a zero value.
- Use an average ranking for repeated values. For example if the 3rd, 4th, 5th, 6th ranks all had the same score, all of their ranks would be 4.5, which is the average rank.
Example Two
We will walk through another in-depth example of this so you can understand exactly how to perform a Wilcoxon signed rank test, if you need to. For this we will create a hypothetical set of data in vCalc called "Effects of Pain Relievers A and B" located HERE. This example will explain a 10-rank Wilcoxon test, but you can do it with any number of ranks.
Data Conversion
The first step to perform a Wilcoxon signed rank test is to convert your data from values into ranks. The ranks are based on the absolute values of the differences between the two treatments. To do this for the Pain Relievers example, we order the differences (which are -3, 3, 2, -5, -2, 11, -1, -8, 3, -6) in ascending order using the absolute values: 1, 2, 2, 3, 3, 3, 5, 6, 8, 11. And the ranks are assigned in ascending order, with 1 corresponding to 1 and 10 corresponding to 11.
Tied Scores
If two or more of your values are the same, they are tied scores, and there are special instructions for ranking them. In the Pain Relievers example, we have two scores of 2 and three scores of 3. To get the tied rank, we simply take the average of the position ranks. For the scores of 2, the position ranks are 2 and 3. `2 + 3 = 5`, `5 /2 = 2.5.` For the scores of 3, the position ranks are 4, 5, and 6. `4 + 5 + 6 = 15`, `15 /3 = 5`. The final ranks used for this dataset are: 1, 2.5, 2.5, 5, 5, 5, 7, 8, 9, 10.
Identifying Signs
After the absolute values have been ranked, they have to be separated into the ranks associated with positive differences and those with negative differences. For the Pain Relievers example, the positive differences are 3, 3, 2, and 11. These values correspond to the ranks of 2, 5, 5, and 10. The other values are classified as negative differences, and the ranks are 1, 2, 5, 7, 8, and 9.
Next we have to add up the positive and negative difference ranks separately to get two sums of ranks, or `sum R`s. The `sum R` for the positive differences is `2.5 + 5 + 5 + 10 = 22.5`. The `sum R` for the negative differences is `1 + 2.5 + 5 + 7 + 8 + 9 = 32.5`.
The Wilcoxon T value is the smaller of the two sums of ranks. In this case, the Wilcoxon T = 22.5.
Determining Significance
Now that we have obtained a T value of 22.5, we have to consult a Wilcoxon table of T values. On this table, the critical T indicates the maximum value for there to be significance; obtained T values must be equal to or less than the value in the table in order for results to be considered significant. For a sample of 10, we see the critical T at alpha = .05 for a two-tailed test is 8, and for a one-tailed test is 10. We have a T value of 22.5, which means we do not have a significant Wilcoxon signed rank test.
References
Gravetter, F. J., & Wallnau, L. B. (2013). Statistics for the Behavioral Sciences. Wadsworth, CA: Cengage Learning.

The Psychology and Statistics Calculator contains useful tools for Psychology Students. The psychology statistics functions include the following:
- Wilcoxon Signed Rank Test: Enter two sets, whether it's a one or two tail test and an alpha value to see the Wilcoxon statistic and the critical value.
- Bayes' Theorem for Disease Testing: Enter a base rate probability, probability of false positives and the probability of correct positives to see a ratio of people with the disease, approximate number of false and true positives and the theorem's percent likelihood of a having the disease if tested positive.
- chi-square Test: Enter a 3x2 matrix to see the expected values matrix with row and column totals, degrees of freedom and the chi-square value.
- Rescorla-Wagner Formula (alpha and beta version): Enter salience for conditional stimuli, rate of unconditional stimuli, maximum conditioning for unconditioned stimuli and the total associative strength of all stimuli present to see the change in strength between conditional and unconditional stimuli.
- Rescorla-Wagner Formula (k version): Enter Maximum conditioning possible for the unconditioned stimuli, total associative strength of all stimuli present, combined salience of the conditioned and unconditioned stimuli, and number of trials to see the change in strength associated with the trials.
- Ricco's Law: Enter the area of visually unresolved target and constant of background luminance when eyes are adapted to see Ricco's Law factor.
- Ricco's Law (K variable): Enter the scotopic vision constant, background luminance and photopic vision constant.
- Stevens' Power Law: Enter proportionality constant, magnitude of stimulation, type of stimulation exponent to see magnitude of sensation.
- Weber Fraction: Enter just-noticeable difference for intensity and stimulus intensity to see the weber fraction.
- Weber-Fechner's Law: Enter just-noticeable difference for intensity, instantaneous stimulus, stimulus intensity and the threshold to see the factor.
- Random Integer: This provides a random number (integer) between a lower and upper bound.
- Observational Statistics (aka Simple Stats): Observational statistics on a set including: count, min, max, mean, median, mode, mid-point, range, population and sample variance and standard deviation, mean absolute deviation, standard deviation of mean, sum of values, sum of squared values, square of the sum, and the sorted set.
- Frequency Distribution: Frequency distribution of a set of observations in uniformly sized bins between a minimum and maximum.
- Least-squares Trend Line (aka Linear Regression): Linear regression line on a set of paired numbers and see (r) the correlation coefficient,(n) number of observations, (μX) mean of the X values, (μY) mean of Y values, (ΣX) sum of the X values, (ΣY) sum of the Y values, (Σ(X⋅Y) ) sum of the X*Y product values, (ΣX2) sum of X2 values, (ΣY2) sum of Y2 values, (a) y intercept of regression line, and (b) slope of regression line.
- Single-Sample t-test: t-Test parameters including alpha level, population mean and whether it's one or two tailed and see the degrees of freedom, critical t-value, t score and the standard error.
- Paired Sample t-test: Test of two sets of values with an alpha level and whether it's one or two tailed and see the number of observations, mean and standard deviation for both sets, the degrees of freedom, critical t-value, t-score and the Standard Error value.
- Effect Size (r-squared): Enter a t-test result and the degrees of freedom to see r2.
- Effect Size (Cohen's d): Enter the mean from two groups and the estimated standard deviation to see the effective size.
- Analysis of Variance (one way): ANOVA for numeric observations of three groups. Computes the F Score, Numerator: degrees of freedom Between, Denominator: degrees of freedom Within, mean of each group, grand mean, total sum of squares, sum of square within and between, and variance within and between.
Statistics Calculators
- Observational Stats: This function accepts a table (rows and columns separated by commas) of numbers and calculates observational statistics for any of the columns. This includes count, min, max, sum, sum of squares (Σx²), square of the sum (Σx)², mean, median, mode, range, mid point, rand, sort up, sort down, rand, population variance, population standard deviation, the sample/experimental variance, sample/experimental standard deviation.
- Simple Stats: This is also provides a full set of observational stats, but on a single row of numbers separated by commas. The observational stats include count, min, max, sum, sum of squares (Σx²), square of the sum (Σx)², mean, median, mode, range, mid point, rand, sort up, sort down, rand, population variance, population standard deviation, the sample/experimental variance, sample/experimental standard deviation.
- Frequency Distribution: This function lets you enter a string of numbers separated by commas, a low and high range and a number of bins. It then computes how many of the observations are in each of the bins between the high and low values designated.
- Paired Sample t-test: This computes the various parameters associated with the Paired Sample t-test.
- ANOVA (one way): The computes the F Score and details for one way analysis of variance for a nxm matrix of observations.
- (χ2) Chi-Square Test: This computes the Chi-Square value for an nxm array of data and provides the degrees of freedom.
- Linear Regression
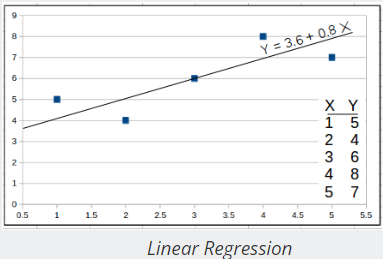 : This computes the regression line (least-squares) through a set of X and Y observations. It also computes the regression coefficient (r).
: This computes the regression line (least-squares) through a set of X and Y observations. It also computes the regression coefficient (r). - Least-squares Trend Inference : This is a linear equation used with Linear Regression to compute a predicted value of Y based on X.
- Wilcoxon Signed Rank Test: This provides the Wilcoxon statistics and critical value for two groups of numeric observations based on an alpha value and whether it's a one or two tailed test.
- Slope-Intercept form of a Line: This provides the slope intercept form (y = mx+b) of a line based on two coordinates.
- Slope between two points: This provides the slope between two coordinates.
- Linear Equation: This computes the range (y) of a linear equation (y = mx +b) and includes a graphing function.
- Probability between z SCORES:
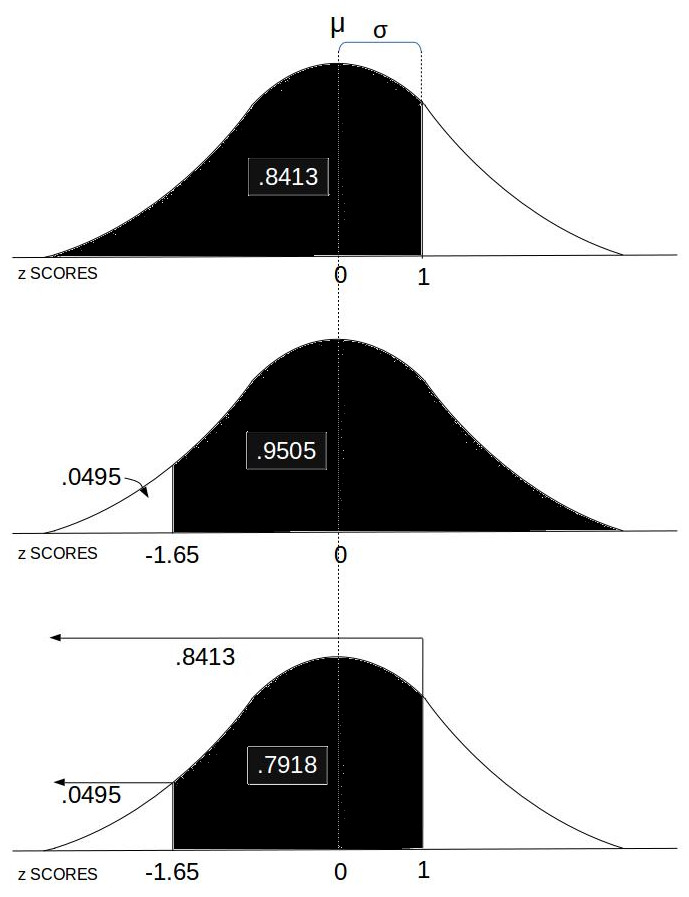 This computes the area under the Normal Distribution curve between two z SCOREs which equates to the probability of an event in that range.
This computes the area under the Normal Distribution curve between two z SCOREs which equates to the probability of an event in that range. - Stats Calc: College level statistics calculator with a bundle including most of the functions in this list.
- Count: This computes the number (n) of observations in a set of numbers.
- Minimum: This computes the minimum (min) value in a set of numbers.
- Maximum: This computes the maximum (max) value in a set of numbers.
- Numeric Sort: This sorts (ascending or descending) a set of comma separated numerical observations.
- Random Sample (k items): The provides a random subset of a specified size (k) in a set of comma separated numerical observations.
- Random Real Number in Range: The provides a random real number between two specified real numbers (upper and lower bounds).
- Radom Integer: The provides a random integer between two specified integers (upper and lower bounds).
- Frequency Distribution: This provides a frequency distribution table for a comma separated set of numbers with a specified number of frequency bins between a lower and upper data range.
- Sum (Σx): This is computes the sum of the values in a set.
- Sum of Squares (Σx²): This computes the sum of the squared values in a set.
- Sum Squared (Σx)²: This computes the square of the summed values in a set.
- Mean (μ): This computes is the mean (average) of values in a set.
- Median: This identifies the middle ordered value in a set of numbers.
- Statistical Mode: This identifies the most recurring observation in a set of numbers.
- Mid Point: This is identifies the mid point of the observation range in a set of numbers.
- Range: This is computes the difference between the max and the min values in a set of number.
- Population Variance (σ2): This computes the variance, a metric regarding the spread of values, for a population set of numeric values.
- Population Standard Deviation (σ): This computes the standard deviation for a population set of numeric values.
- Sample Variance (s2) : This computes the variance, a metric regarding the spread of values, for a sample set of numeric values within a greater population.
- Sample Standard Deviation (s): This computes the standard deviation for a sample set of numeric values within a greater population.
- z SCORE Formula: This computes the z SCORE for a value base on the mean and standard deviation.
- z SCORE: This computes the z SCORE for a value (Raw Score) based on a set of values, and whether that set is sample or population.
- Percentile: This computes the percentile of a value (y) in a set (X) of values.
- Standard Deviation of Mean (SDOM): This computes the standard deviation of mean, sometimes also known as the standard error of the mean (SEM), useful to helps quantify the uncertainty in the estimate of the mean.
- Percent Relative Standard Deviation (%RSD): This computes the percent relative standard deviation, also known as the coefficient of variation (CV). The %RSD is a measure of the dispersion of a probability distribution.